Drone Object Avoidance
This is a short summary of the work performed by James M. Ballow and some colleagues at Clarkson University (Potsdam) for an advanced machine learning course tought by professor Soumyabrata Dey in 2022. This page serves to give an over-simplified presentation of the work conducted during this course to exemplify the knowledge acquired from the course.

Project Goal
Use machine learning in conjunction with computer vision to yield an algorithm that can detect an object and identify the object during flight so as to avoid collision with the object.
Planning
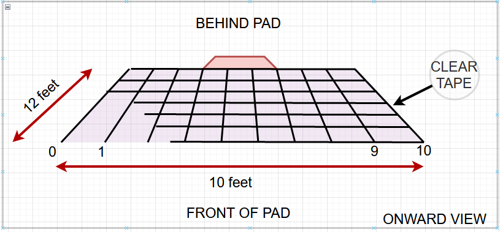
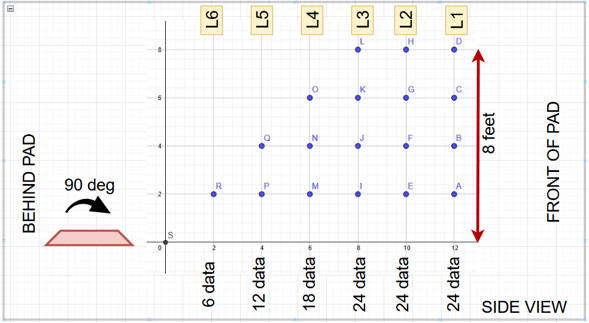
These are some data collection methods employed in the project. The idea is to collect images of the object that is to be avoided (cardboard box) and to do so in a manner that gives a different vantage point of the object relative to the frame border. The idea was also to ensure that a consistent and generous amount of the object was observed so as to not impose a sub-categorical bias (i.e., favor of one vantage of a kind of object instead of all vantages).
L6





L4





L2





Data Collection
Using the drone itself, images were taken by placing the drone on each of the gridded intersections starting the drone and allowing it to naturally drift up off of the ground. Using remote control, the drone was raised higher to achieve the correct arial height. This was repeated at each gridded intersection to collect samples from all planned vantages. Here are some samples of the data collected at a few of the intersections.
Training Image Preparation
The objective was to identify a particular object (i.e., a box) within an image. Obviously,
there will
be more than just a box in an image, so to train a machine we prepared two pools of images:
(1) those
that contain the box of interest, and (2) those than contain anything that is not a box
(shapes and textures
throughout the room). We used python, and manual image segmentation and
labeling to obtain
the images containing the boxes, and we used random box generation generation to obtain
differently-sized
background images throughout the room.
We greyscaled the images to shrink the feature space because it was impractical in a semester to obtain enough samples to include a 16-bit color space in combination with extensive textures. Then images were resized to 100x100 pixels so as to allow for use of a fixed-size CNN.
Finally, to reduce our bias, we increased the number of textures and orientations using additional augmentation including translation, rotation, and flipping to fill out the feature space with non-object (background) samples.





Results
After training with thousands of images taken from different rooms and different vantage points, the drone was flown on its own to gather images which reported back to a remote location running software to receive the images. Due to processing time, the images were read at a frequency of 1 image per 5 images reported. Using randomized bounding boxes and the trained machine learning model, sub-images of the object of interest were identified and printed to screen for us to observe what the drone understands as being the location of the object of interest. The project, peformed in a matter of weeks, was a success in that the drone was able to clearly "see" the object of interest at many vantages points.
Future Work
- A different machine learning model can be created for each kind of environment that the drone would travel (e.g., in a forest, in a home, in an office, in the dark, in a mountain region) and the algorithm could change between these model sets to provide an accurate model to discern the object of interest.
- It would be interesting to incorporate a depth detection device to allow for another feature in the feature space. Understanding the depth of the object you have bounded will inform the algorithm about how close the drone can move towards that object. This is to say that the assumption of a fixed-size object can be eliminated, because depth and xy-bounding box yield true spacial orientation.
References
- R. Girshick, J. Donahue, T. Darrell and J. Malik, "Region-Based Convolutional Networks for Accurate Object Detection and Segmentation," in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 1, pp. 142-158, 1 Jan. 2016, doi: 10.1109/TPAMI.2015.2437384.
- K. E. A. van de Sande, J. R. R. Uijlings, T. Gevers and A. W. M. Smeulders, "Segmentation as selective search for object recognition," 2011 International Conference on Computer Vision, Barcelona, Spain, 2011, pp. 1879-1886, doi: 10.1109/ICCV.2011.6126456.